Matrix Multiplicative Weights Update Method
A few days ago, I watched a lecture of Madhur Tulsiani on multiplicative weight update method and its applications to solving LPs. In this post, I am going to briefly describe about this. You can find the talk here.
Problem Statement
Consider a system of 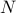 experts labelled
experts labelled  . There's a player who chooses an expert, say
. There's a player who chooses an expert, say 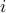 , and bears a loss equal to the loss of expert . The losses of each of the expert are revealed only after the player chooses the expert. This game continues on for, say,
, and bears a loss equal to the loss of expert . The losses of each of the expert are revealed only after the player chooses the expert. This game continues on for, say, 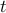 rounds. The losses of each expert will be different in different round. The player's strategy is to choose the experts in each round such that his total loss is minimized.
rounds. The losses of each expert will be different in different round. The player's strategy is to choose the experts in each round such that his total loss is minimized.
Example
As an example, let 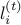 denote the loss associated with expert at time . We can have the following possible scenario:
denote the loss associated with expert at time . We can have the following possible scenario:
| Experts | 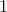 | 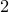 |  | |
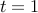 | 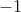 | | | |
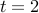 | | | |
|
Since the don't have complete information of the losses of each expert a prior, minimizing total loss makes little sense. Instead, we will try devising an algorithm where we perform as good as the best expert.
Greedy Algorithm
We will now prove that Greedy Algorithm can perform arbitrarily worse. Consider the following example:
| Experts | | | 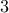 | | |
| | | | | | |
| | | | | | |
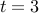 | | | | | |
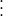 | |||||
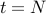 | | | | |
|
wlog assume greedy algorithm picks the expert in following manner: Expert , Expert and so on. Clearly, this strategy accumulates a huge loss. The best strategy is to pick Expert at each stage.
MMW Algorithm
We will now describe the overall idea of MMW Algorithm:
Maintain weights
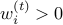 .
.Output distribution
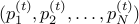 at every step. Note that
at every step. Note that 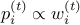 .
.Loss at time
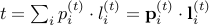 .
.
The only remaining question is how to define 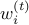 and update them. There can be various possible approaches but the one we are going to use is based on Hedge Algorithm.
and update them. There can be various possible approaches but the one we are going to use is based on Hedge Algorithm.
Hedge Algorithm
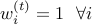
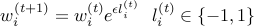
Analysis
For the analysis of this function, we will define a potential function and compare the upper and lower bounds of loss.
The potential function is defined as:
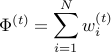
Lower bound
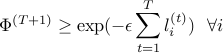
The above inequality follows from the fact that right hand quantity is 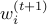 and each of the 's is positive.
and each of the 's is positive.
Upper bound
For the upper bound, we will be needing the following inequalities:
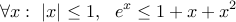
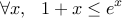
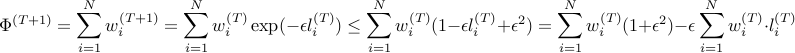
The second last line follows from using the above mentioned inequality and also the fact that 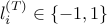 . Using the fact that
. Using the fact that 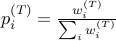 , we can write
, we can write 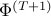 as
as
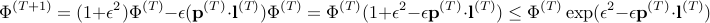
Unfolding the 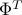 , we obtain that
, we obtain that
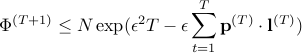
Using the two bounds obtained and taking 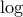 of both sides, we obtain,
of both sides, we obtain,
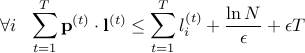
The above inequality states that the loss incurred by our algorithm is worse off than the lost incurred by any expert (in particular, the best expert) by an additive factor which is independent of the expert's losses and depends only on the number of experts and rounds.
To view the above loss per round, divide the whole equation by 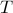 .
.
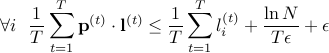
Hence, as the number of rounds () increases, the algorithm performs better and the error drops. In fact, it can be shown that for 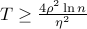 ,
,
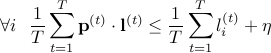
Exercises
A few exercises which can be tried out to fully internalize the concept:
Generalize for
![l_i^{(t)} in [-1,1]](eqs/8626947802440990825-130.png) .
.What if
![l_i^{(t)} in [-rho,rho]](eqs/6725424298475802099-130.png) .
.Using the update rule
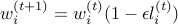 and , prove that
and , prove that 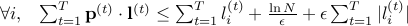 .
.Suppose
![l_i^{(t)} in [0,rho]](eqs/6540227361925785915-130.png) . Using the same update rule as above, prove that for
. Using the same update rule as above, prove that for 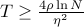 ,
, 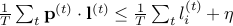 .
.